個人的にはLLM、AI以前に人間の方がはるかにヤバイ
と感じた一場面で死した
ひとつ、以前、NHKのニュース番組の特集の中で、小学校における、小学生低学年だったかと思いますが、授業、教育で、
・AIは嘘をつきます。
小学生 AIは嘘をつく
・気をつけましょう
小学生 簡単に信じません。気をつけます
… というような場面があったことを思い出しました。
嘘をつく。
という時点であきらかに先生の誤りであり(先生の嘘ではなく誤り)
そこから誤りが積み重なっていた事象を目の当たりにした。
と私は思いました。この点に関して考察をお願い致します。
(子供にわかりやすく言うつもりがこうなたと思いますが)
ChatGPT o3 でもこんなこともやってくれるのですね…
$1
LLMのしくみ(学習~推論)
LLM(大規模言語モデル)は、まず大量のテキストデータを使って「どんな文脈でどんな単語が現れるか」を学習(Pretraining)します。その後、特定用途の追加データでファインチューニングされる場合もあります。実際の利用時(推論時)は、入力された文脈に対して次に出る単語を確率的に予測し、文章や応答を生成します。
- 学習(Pretraining):大量のテキストから文脈と単語のパターンを獲得。
- ファインチューニング:追加データで目的別に学習することも。
- 推論:利用時に確率的に単語を並べて応答を生成(=事実を「知っている」わけではない)。
このため、LLMはもっともらしい出力は得意ですが、事実や論理的整合性を常に保証するものではありません。
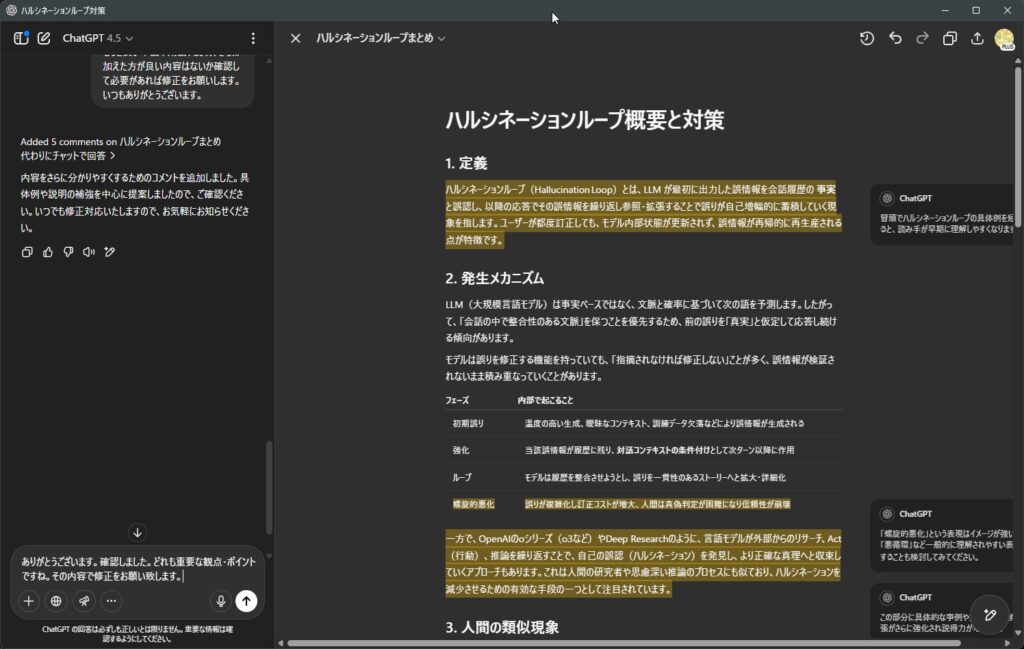
1. 定義
ハルシネーションループ(Hallucination Loop)とは、LLM が最初に出力した誤情報を会話履歴の 事実 と誤認し、以降の応答でその誤情報を繰り返し参照・拡張することで誤りが自己増幅的に蓄積していく現象を指します。ユーザーが都度訂正しても、モデル内部状態が更新されず、誤情報が再帰的に再生産される点が特徴です。
例えば、AIが存在しない製品を一度誤って生成すると、その後の会話でその製品に関する詳細や仕様まで作り出してしまうことがあります。
$1
マルチモーダルLLMの仕組み
マルチモーダル LLM とは、「テキスト」だけでなく、「画像・音声・動画」など複数の種類(モダリティ)のデータを一つのモデルで処理し、理解・生成できるLLMです。
仕組みと特徴
- テキスト・画像・音声など、異なる形式の入力をそれぞれ専用のエンコーダで特徴量ベクトルに変換し、モデル内部で統合します。
- 統合された表現をもとに、テキスト生成や画像の説明、逆に画像生成など、多様な出力が可能です。
- 推論時は「テキスト×画像」「音声×テキスト」など、異なる入力組み合わせにも柔軟に対応できます。
| 項目 | 内容 |
|---|---|
| モデル名 | マルチモーダル LLM |
| 入力形式 | テキスト、画像、音声、動画 など |
| 動作原理 | 入力ごとに特徴量へ変換 → 共通の意味空間で統合 → 出力生成 |
| 強み | 複雑な状況理解や多様なメディアを横断した生成が可能 |
| 主な用途 | 画像説明、画像生成、音声認識、多モーダル質問応答 など |
2. 発生メカニズム
LLM(大規模言語モデル)は事実ベースではなく、文脈と確率に基づいて次の語を予測します。したがって、「会話の中で整合性のある文脈」を保つことを優先するため、前の誤りを「真実」と仮定して応答し続ける傾向があります。
モデルは誤りを修正する機能を持っていても、「指摘されなければ修正しない」ことが多く、誤情報が検証されないまま積み重なっていくことがあります。
| フェーズ | 内部で起こること |
|---|---|
| 初期誤り | 温度の高い生成、曖昧なコンテキスト、訓練データ欠落などにより誤情報が生成される |
| 強化 | 当該誤情報が履歴に残り、対話コンテキストの条件付けとして次ターン以降に作用 |
| ループ | モデルは履歴を整合させようとし、誤りを一貫性のあるストーリーへと拡大・詳細化 |
| 悪循環的悪化 | 誤りが複雑化し訂正コストが増大、人間は真偽判定が困難になり信頼性が崩壊 |
一方で、OpenAIのoシリーズ(o3など)やDeep Researchのように、言語モデルが外部からのリサーチ、Act(行動)、推論を繰り返すことで、自己の誤認(ハルシネーション)を発見し、より正確な真理へと収束していくアプローチもあります。例えば、外部のデータベースを参照して誤情報を発見・修正する Retrieval-Augmented Generation (RAG) や、自己評価を繰り返して修正を行う Self-Reflection の手法があります。
3. 人間の類似現象
日本語の慣用句「嘘の上塗り」に相当し、誤りを隠すためにさらなる誤りを重ねた結果、自縄自縛に陥る心理的プロセスと類似しています。
実際に日本の教育現場でも、教師が「AIは嘘をつく」という表現を使用してしまう例があります。これは「嘘をつく」という意図的な行為ではなく、「誤った情報を生成する可能性がある」という事実を適切に伝えきれていないケースです。このような教師自身の誤認識や言葉の選択ミスから、生徒・学生が誤った認識を持ち、それが教育の現場で定着してしまう可能性があります。この事例は、ハルシネーションループが技術的な問題だけでなく、人間の誤解や言葉遣いの誤りから社会的・教育的にも広がる可能性があることを示しています。
4. 影響
- 信頼性低下:長い対話ほど誤差伝搬が顕著。
- 意思決定リスク:誤情報に基づく判断を誘発。
- ブランド毀損:顧客向けチャットボットで発生すると企業イメージ悪化。
5. 検出指標・サイン
- 応答内で引用元が示されない、または一貫しない。
- モデルの確信度(対数尤度)が高いのに事実誤認が多い 1。
- 時系列で内容が徐々に“物語化”し詳細が増殖。
6. 主要要因
- 会話ステートの蓄積:LLM は直近の履歴に過度に依存。
- ユーザーの確証バイアス:誤りを肯定する追従質問が強化学習的フィードバックに。
- 外部検証の欠如:RAG やツール呼び出しが無い純粋生成モード。
- モデル自己評価の欠陥:自己の出力を再評価し、矛盾や不確実性を修正する能力が不足している。
7. 具体的対策
7.1 セッション設計
- リセット:誤り検知時に新スレッドを開始し会話履歴を切り離す。
- 有限履歴ウィンドウ:直近 N ターンのみをコンテキストに含める。
7.2 プロンプト工夫
- 明示的検証指示
あなたは自分の出力をステップごとに検証してください。 出典が無い場合は「不明」と回答し、推測は避けること。 - 自省ループ (Self-Reflection):一度生成させた後、別ロールで事実チェックを強制 2。
7.3 システム実装レベル
| 手法 | 概要 | 長所 | 短所 |
|---|---|---|---|
| Retrieval-Augmented Generation (RAG) | 外部 KB で検証しながら生成 | 事実整合性向上 | KB が最新でないと逆効果 |
| Self-Consistency Voting | 複数サンプルを生成し多数決 | 低温度でも多様性確保 | 計算コスト増 |
| Uncertainty Filtering | 応答のエントロピーを計算し、不確実性が高い場合には再生成を行うなどの対策を実施 | 誤情報露出を大幅削減 3 | 判定閾値チューニング(例えば、エントロピー閾値の設定)が必要 |
| Human-in-the-Loop | 重要応答を人間審査 | 最高の信頼性 | スケールしにくい |
7.4 運用ガイドライン
- 重要ドメインでは常に出典リンクを必須化。
- 会話を分割し、論点が変わるたびに新スレッドを推奨。
- ログ監査で誤情報をモニタリングし、プロンプト/設定を早期修正。
8. プロンプト例:再発防止テンプレート
System: あなたは専門家です。次の制約を守ってください。
1. 不確かな場合は「不確か」と答える。
2. 事実を述べる際は最新の出典を JSON で添付。
3. 出力後、\"SELF-CHECK:\" セクションで矛盾が無いか検証。
9. 参考文献・リソース
- H. Ye et al., “Towards Mitigating Hallucination in Large Language Models via Self-Reflection,” Findings of EMNLP 2023 2
コメントを残す